Title: Quasar benchmarks
1. Custom benchmarks
As a first case, we implemented three algorithms in both directly in CUDA and in Quasar as custom benchmarks, and we compare both the development times and the execution times of the algorithms:
The first algorithm, filter, implements a convolution with a 1x32 row filter on an image of size 512x512. We compare different memory access strategies (global memory versus shared memory). [CUDA source code] [Quasar source code]
In the second algorithm, surfwrite, a 2D separable 32x32 filter is applied to an image of size 512x512. Here, the use global memory is compared to the use of CUDA surfaces/textures. [CUDA source code] [Quasar source code]
In a third algorithm, tex4, a vertical wavelet filter is aplied to an image, again with different memory access strategies. [CUDA source code] [Quasar source code]
The execution times for a Geforce GTX780M (Kepler), lines of code (LOC) and development times are given in the table below. It can be noted that, for about 3x less code and a significant lower development time, the resulting execution times are very close to the CUDA implementations of the algorithm.
| Test program | CUDA - time (ms) | Quasar - time (ms) | CUDA - LOC | Quasar - LOC | CUDA - Dev time | Quasar - Dev time | Description | Runs of the algorithm |
| filter (1) | 3042.29 | 3051.174 | 140 | 61 | 1h20 | 0h15 | Filter 32 taps, with global memory | 10000 |
| filter (2) | 958.832 | 831.0475 | Filter 32 taps, with shared memory | 10000 | ||||
| surfwrite (1) | 4998.2 | 5056.289 | 195 | 61 | 1h30 | 0h20 | 2D spatial filter 32x32 separable, with global memory | 10000 |
| surfwrite (2) | 2144.71 | 2286.131 | 2D spatial filter 32x32 seperable, with texture & surface memory | 10000 | ||||
| tex4 (1) | 410.23 | 518.0296 | 348 | 120 | 3h50 | 0h30 | wavelet filter, with global memory | 1000 |
| tex4 (2) | 384.548 | 386.0221 | wavelet filter, with global memory & float3 | 1000 | ||||
| tex4 (3) | 486.875 | 352.0201 | wavelet filter, with texture memory (1 component) | 1000 | ||||
| tex4 (4) | 119.801 | 170.0098 | wavelet filter, with texture memory (RGBA) | 1000 |
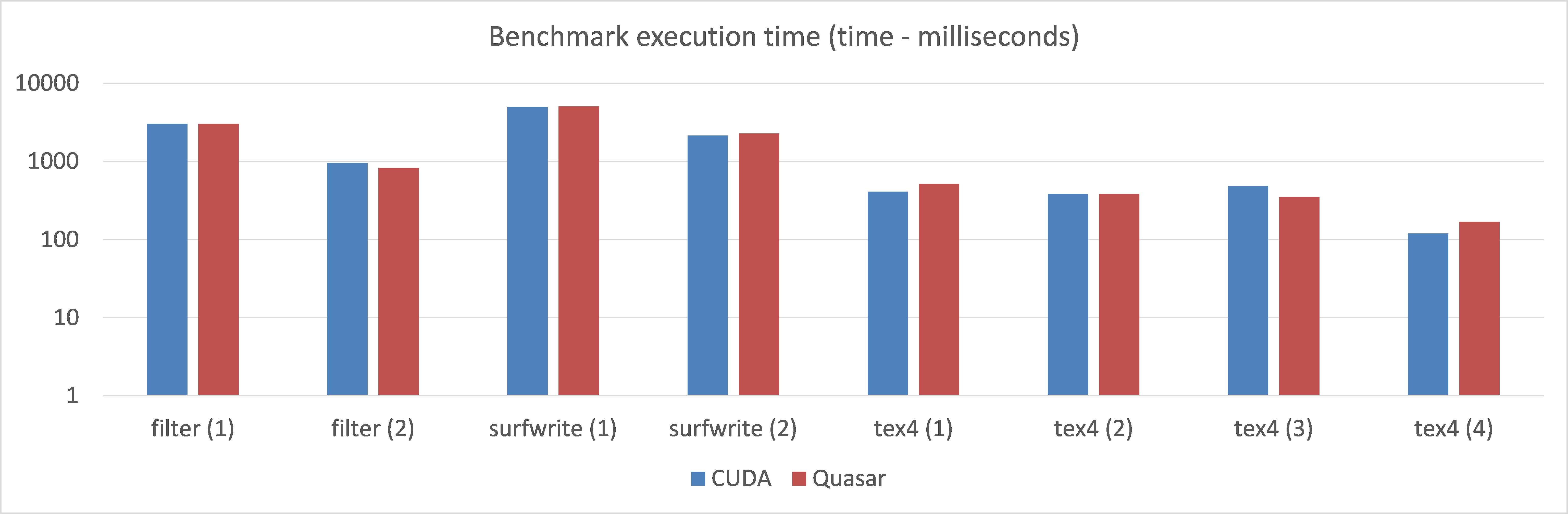 Figure 2. Comparison of the execution times of various test programs
Figure 2. Comparison of the execution times of various test programs
Comments:
Note that the Quasar front-end compiler here generates CUDA code; another important aspect is the run-time system, which transparently handles many host-side aspects of CUDA (via the CUDA driver API). The above benchmarks hence focus on specific programming patterns that are commonly used in image/video and biomedical imaging algorithms, and benchmark both the quality of the code generated by the Quasar front-end compiler and the efficiency of the run-time, compared to a manual implementation directly in CUDA.
We obtained similar results for other GPUs such as the desktop Geforce GTX 980 (Maxwell): the absolute times are faster, but in relative terms, the same trends are observed.
Although this is far from a complete benchmark set, it gives a good indication of development effort in terms of lines of code/programming complexity, versus computational performance of the resulting algorithm.
#2. A more complex test-case
In a second test-case, an experienced independent researcher at a different university implemented an MRI reconstruction algorithm (parallel MRI reconstruction for spiral grid trajectories) in CUDA in a period of three months. Simultaneously, a researcher of the UGent/IPI research groups 1) learned how to use Quasar from the ground up (he did not use Quasar before) and 2) implemented exactly the same algorithm in Quasar. This was achieved in a period of three days! Below are some computation time results obtained for different data set sizes:
| MRI Image size | k-space samples | CUDA developer | Quasar developer |
| 128x128 | 32x128 | 2.0 ms | 1.9 ms |
| 256x256 | 32x256 | 2.0 ms | 2.4 ms |
| 256x256 | 64x256 | 3.0 ms | 2.8 ms |
| 256x256 | 128x256 | 4.0 ms | 3.6 ms |