Dynamic Memory Allocation on CPU/GPU
In some algorithms, it is desirable to dynamically allocate memory inside __kernel__ or __device__ functions, for example:
When the algorithm processes blocks of data for which the maximum size is not known in advance.
When the amount of memory that an individual thread uses is too large to fit in the shared memory or in the registers. The shared memory of the GPU consists of typically 32K, that has to be shared between all threads in one block. For single-precision floating point vectors
vecor matricesmatand for 1024 threads per block, the maximum amount of shared memory is 32K/(1024*4) = 8 elements. The size of the register memory is also of the same order: 32 K for CUDA compute architecture 2.0.
Example: brute-force median filter
So, suppose that we want to calculate a brute-force median filter for an image (note that there exist much more efficient algorithms based on image histograms, see immedfilt.q). The filter could be implemented as follows:
we extract a local window per pixel in the image (for example of size
13x13).the local window is then passed to a generic median function, that sorts the intensities in the local window and returns the median.
The problem is that there may not be enough register memory for holding a local window of this size. 1024 threads x 13 x 13 x 4 = 692K!
The solution is then to use a new Quasar runtime & compiler feature: dynamic kernel memory. In practice, this is actually very simple: first ensure that the compiler setting “kernel dynamic memory support” is enabled. Second, matrices can then be allocated through the regular matrix functions zeros, complex(zeros(.)), uninit, ones.
For the median filter, the implementation could be as follows:
% Function: median
% Computes the median of an array of numbers
function y = __device__ median(x : vec)
% to be completed
endfunction
% Function: immedfilt_kernel
% Naive implementation of a median filter on images
function y = __kernel__ immedfilt_kernel(x : mat, y : mat, W : int, pos : ivec2)
% Allocate dynamic memory (note that the size depends on W,
% which is a parameter for this function)
r = zeros((W*2)^2)
for m=-W..W-1
for n=-W..W-1
r[(W+m)*(2*W)+W+n] = x[pos+[m,n]]
endfor
endfor
% Compute the median of the elements in the vector r
y[pos] = median(r)
endfunctionFor W=4 this algorithm is illustrated in the figure below:
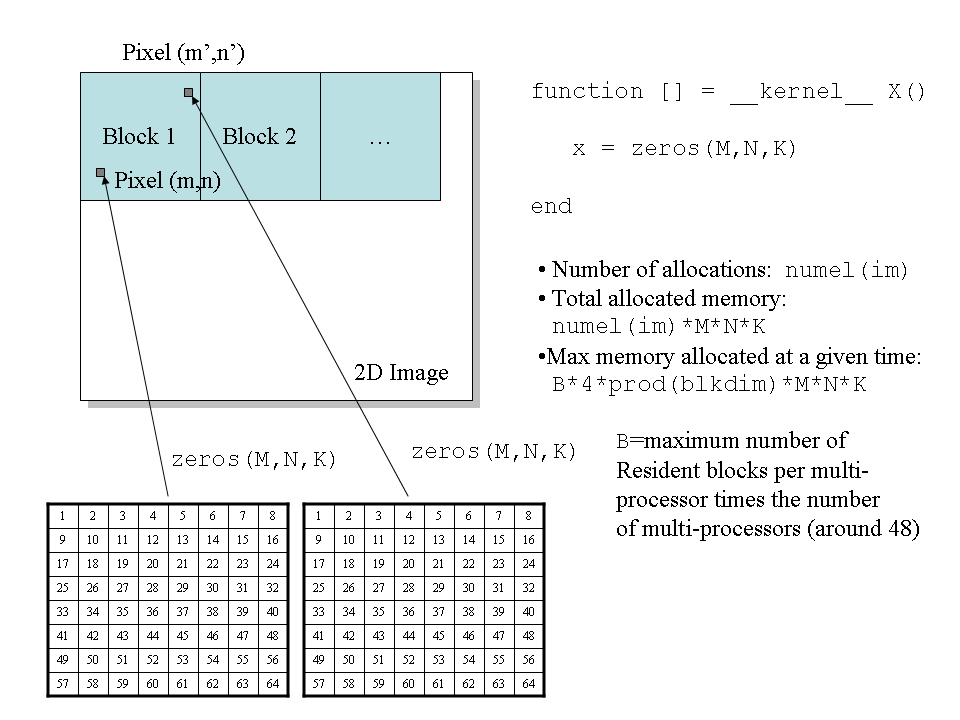 Figure 1. dynamic memory allocation inside a kernel function.
Figure 1. dynamic memory allocation inside a kernel function.
Parallel memory allocation algorithm
To support dynamic memory, a special parallel memory allocator was designed. The allocator has the following properties:
The allocation/disposal is distributed in space and does not use lists/free-lists of any sort.
The allocation algorithm is designed for speed and correctness.
To accomplish such a design, a number of limitations were needed:
The minimal memory block that can be allocated is 1024 bytes. If the block size is smaller then the size is rounded up to 1024 bytes.
When you try to allocate a block with size that is not a pow-2 multiple of 1024 bytes (i.e.
1024*2^NwithNinteger), then the size is rounded up to a pow-2 multiple of 1024 bytes.The maximal memory block that can be allocated is 32768 bytes (=2^15 bytes). Taking into account that this can be done per pixel in an image, this is actually quite a lot!
The total amount of memory that can be allocated from inside a kernel function is also limited (typically 16 MB). This restriction is mainly to ensure program correctness and to keep memory free for other processes in the system.
It is possible to compute an upper bound for the amount of memory that will be allocated at a given point in time. Suppose that we have a kernel function, that allocates a cube of size M*N*K, then:
max_memory = NUM_MULTIPROC * MAX_RESIDENT_BLOCKS * prod(blkdim) * 4*M*N*KWhere prod(blkdim) is the number of elements in one block, MAX_RESIDENT_BLOCKS is the maximal number of resident blocks per multi-processor and NUM_MULTIPROC is the number of multiprocessors.
So, suppose that we allocate a matrix of size 8x8 on a Geforce 660Ti then:
max_memory = 5 * 16 * 512 * 4 * 8 * 8 = 10.4 MBThis is still much smaller than what would be needed if one would consider pre-allocation (in this case this number would depend on the image dimensions!)
Comparison to CUDA malloc
CUDA has built-in malloc(.) and free(.) functions that can be called from device/kernel functions, however after a few performance tests and seeing warnings on CUDA forums, I decided not to use them. This is the result of a comparison between the Quasar dynamic memory allocation algorithm and that of NVidia:
Granularity: 1024
Memory size: 33554432
Maximum block size: 32768
Start - test routine
Operation took 183.832443 msec [Quasar]
Operation took 1471.210693 msec [CUDA malloc]
SuccessI obtained similar results for other tests. As you can see, the memory allocation is about 8 times faster using the new apporach than with the NVidia allocator.
Why better avoiding dynamic memory
Even though the memory allocation is quite fast, to obtain the best performance, it is better to avoid dynamic memory:
The main issue is that kernel functions using dynamic memory also require several read/write accesses to the global memory. Because dynamically allocated memory has typically the size of hundreds of KBs, the data will not fit into the cache (of size 16KB to 48KB). Correspondingly: the cost of using dynamic memory is in the associated global memory accesses!
Please note that the compiler-level handling of dynamic memory is currently in development. As long as the memory is “consumed” locally as in the above example, i.e. not written to external data structures the should not be a problem.